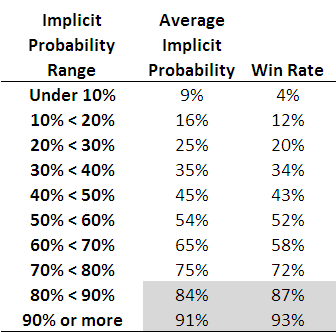
Each row of this table, which is based on all games from 2006 to the present, corresponds to the results for teams with price-implied probabilities in a given range. The first row, for example, is for all those teams whose price-implied probability was less than 10%. This equates, roughly, to teams priced at $9.50 or more. The average implied probability for these teams has been 9%, yet they've won at a rate of only 4%, less than one-half of their 'expected' rate of victory.
As you move down the table you need to arrive at the second-last row before you come to one where the win rate exceed the expected rate (ie the average implied probability). That's fairly compelling evidence for an FLB.
This empirical analysis is interesting as far as it goes, but we need a more rigorous statistical approach if we're to take it much further. And heck, one of the things I do for a living is build statistical models, so you'd think that by now I might have thrown such a model at the topic ...
A bit of poking around on the net uncovered this paper which proposes an eminently suitable modelling approach, using what are called conditional logit models.
In this formulation we seek to explain a team's winning rate purely as a function of (the natural log of) its price-implied probability. There's only one parameter to fit in such a model and its value tells us whether or not there's evidence for an FLB: if it's greater than 1 then there is evidence for an FLB, and the larger it is the more pronounced is the bias.
When we fit this model to the data for the period 2006 to 2010 the fitted value of the parameter is 1.06, which provides evidence for a moderate level of FLB. The following table gives you some idea of the size and nature of the bias.