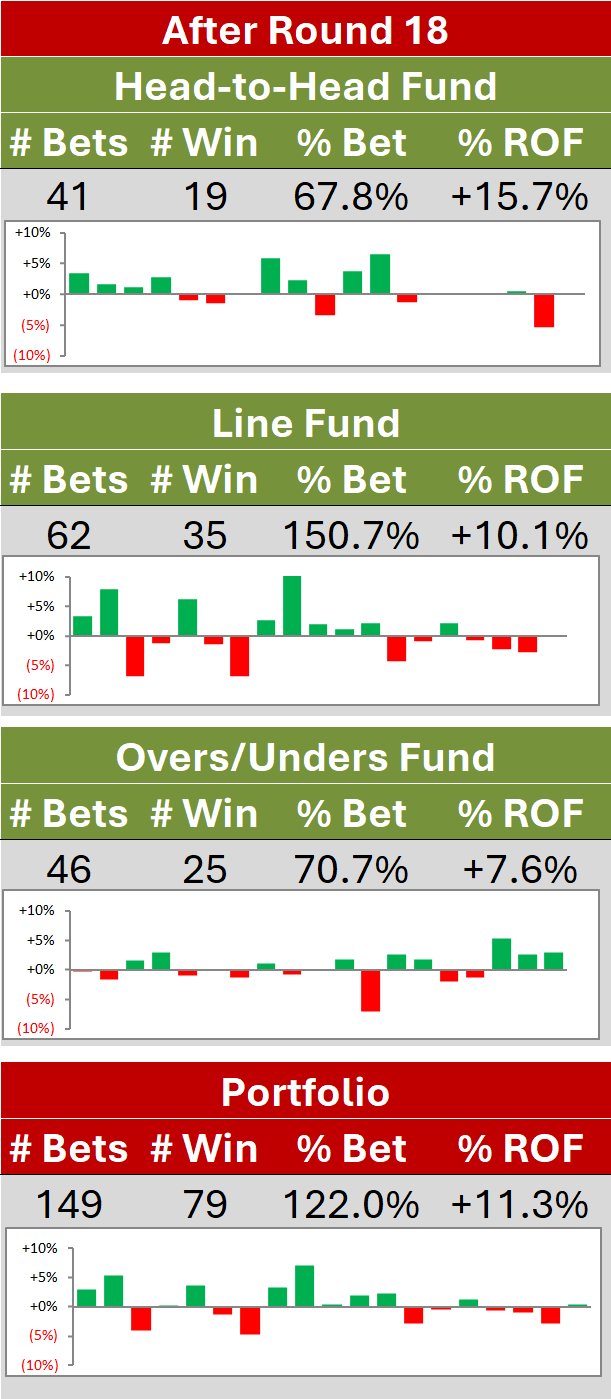
Specialist Margin Prediction: "Bathtub" Loss Functions
/We know that we can build quite simple, non-linear models to predict the margin of AFL games that will, on average, be within about 30 points of the actual result. So, if you found a bet type for which general margin prediction accuracy was important - where every point of error contributed to your loss - then a general model like this would be what you're looking for.
This year we'll be moving into margin betting though, where the goal is to predict within X points of the actual result and being in error by X+1 points is no different from being wrong by X+100 points. In that environment our all-purpose model might not be the right choice.
In this blog I'll be describing a process for creating margin-predicting models that specialise in providing predictions within X points of the final outcome.
Data Inputs
All models will be fitted to the margins for all games across the period 2000 to 2011 and will use as explanatory variables the two team's MARS Rating going into the game, the two team's price with the TAB (actually, for 2000-2005, the price with some bookmaker unknown), and the Interstate Status of the game.
Approximately 50% of games will be used as the training sample, with the remainder used as a holdout sample.
Modelling Approach
Since we're interested in non-linear as well as linear solutions, I'll be calling on the services of the Eureqa application yet again.
The wrinkle this time is in the formulation of the Target Expression (or, more formally, the Loss Function), which will be the following:
1 - less(abs(f(.) - Actual_Margin, M) = 0
where
f(.) = f(Own_MARS, Opponent_MARS, Own_Price, Opponent_Price, Interstate_Status), and
Actual_Margin = Own_Score - Opponent_Score, and
M = the margin of error within which we'll reward predictions
(NB 'Own' refers to the Home team, and 'Opponent' to the Away team)
Let's consider a concrete example and assume that we want to build a model that tips within 5 points of the actual margin. In that case, M = 5.
Here the Target Expression on the lefthand side of the equals sign evaluates to 0 for any games where the absolute difference between the model's prediction - which is f(.) - and the actual margin is less than 5, and evaluates to 1 otherwise. (The building block less(expr,M) evaluates to 1 if expr<M and to 0 otherwise.)

Diagramatically, this loss function is as shown on the left and it has a bathtub shape - though here maybe fit only for stork washing.
Eureqa tries to minimise this Target Expression by choosing an appropriate functional form for f and appropriate coefficients on the explanatory variables within f. Because our loss function evaluates to 0 only when a prediction is within 5 points, and to 1 otherwise, Eureqa cares not whether a prediction is 6 points in error versus 60 points. It will do everything it can to get the absolute predictive error for a game below the threshold of 5, but once it's given up on a game it no longer cares how large the error is. This has the effect of preventing Eureqa from paying too much attention to games where the final margin was very large, very unpredictable, or both.
In contrast, when we use the more standard Target Expressions such as:
- The Squared Error Loss Function: (Actual_Margin - f(.))^2, or
- The Absolute Error Loss Function: abs(Actual_Margin - f(.))
Eureqa is forced to sweat every point of predictive error in every game.
To prevent Eureqa from getting too funky with its selection of functional form, I allowed it only to use the building blocks +, -, *, /, exp, log, ^, sqrt, if, less, less_or_equal, greater, greater_or_equal, min and max.
Results on Holdout Sample
The results for a range of models with different values for the threshold M, which I'll collectively call the 'specialist models', are shown below.
(Please click for a larger image.)
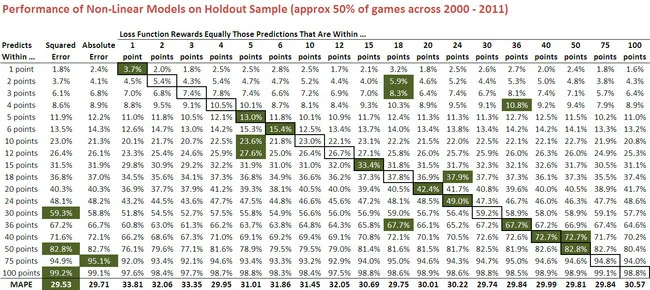
From the fourth column onwards, each column of this table relates to a fitted model for a given value for M. So, for example, the column labelled "5 points" is for the model that is rewarded only when its predictions are within 5 points of the final result. The column labelled "Squared Error" is for the all-purpose model with a squared error loss function, and that labelled "Absolute Error" is for the all-purpose model with an absolute error loss function. These are provided for comparative purposes.
The percentage entries within each column provide the proportion of holdout games for which the relevant model's margin predictions are within X points of the actual result, where X is described in the row under the column headed "Predicted Within ...". So, for example, the predictions of the 3 points specialist model are within 3 points of the actual margin in 7.4% of the holdout games.
Numbers highlighted in green are the maxima for the row, and the outlined cells identify for each model the row that pertains to its "speciality" - that absolute prediction error below which its predictions are rewarded. If the notion of model specialisation has any practical merit, you'd expect many of the outlined cells to also be shaded green. This is the case for 9 of the 18 models shown here and none of the other 9 are more than 1% poorer than the best model in the row.
Comparison of the results for the specialist models with those produced using squared and absolute error loss functions is instructive. The 1 point model - that is, the model that is only rewarded when it predicts within 1 point of the actual result - does what's been asked of it in 3.7% of games, which is about twice as often as the squared error model and about 50% more often than the absolute error model manage to do this. Both in relative and in absolute terms, that's an impressive achievement - and I posit would have proven a profitable basis for margin wagering across the dozen years.
The 2 point model is also impressive, spitting out predictions that are within 2 points of the actual margin 5.4% of the time, a performance that's matched only by the 4 point model which, in striving to predict within 4 points of the actual margin, manages to get within 2 points equally as often.
A few other things worth calling out are:
- The performance of the 5 point model, which not only does best of all models in predicting within 5 points of the actual margin, but also tops all-comers in predicting within 10 points and 12 points.
- The performance of the 36 point model, which wins in its speciality class of predicting within 36 points of the actual margin, but also in predicting within 3 points and within 4 points of the actual margin.
- The squared error model's strong performance at larger absolute prediction errors. It wins the 30, 50, 75 and 100 point categories. What this demonstrates is that, when your loss function penalises you with the square of your error, you can't afford to be in error by more than 30 points very often. In effect, what a squared error loss function does is produce models that specialise in not being terribly wrong terribly often - but not being terribly close terribly often either.
- The fact that the MAPEs of all the specialist models are worse than those of the squared error and absolute error models (see the last row of the table). Some of the specialist models however, especially those with larger values of M, still manage to break 30.
In summary then, it is possible to build models optimised to predict margins within a specified tolerance of the actual result that significantly outperform an all-purpose margin-predicting model, especially for small thresholds.
Fitted Models
What's also interesting is the relative simplicity of many of these models:

The 1 point model is amazingly simple - just add the TAB prices of the two teams, add about one-tenth of a point, and there's your predicted home team margin.
We noted earlier the strong performance of the 36 point model. It's quite simple too: multiply by 18.29 the lesser of 4.354 and the Away team's TAB price, then subtract 36.58 from the result.
Results on the 2011 Holdout Sample Only
One concern you might have, knowing that the models have used bookmaker data from the 2000-2005 period, the provenance of which is more questionable than those for the period 2006-2011, is how well the models might have performed just on the holdout sample of 2011 games.
Here's that information.

You can draw your own conclusions from the results shown here - bearing in mind that they'll be subject to larger sampling variability than the earlier results as they're based on fewer games - but it seems reasonable to claim that they're also encouraging if not generally as strong. The 1, 2 and 5-point specialist models in particular still perform very well.
UPDATE: Alas, things are not quite as rosy as they appear above. A glitch in the software that I was using to create these results meant that some of the holdout data was able to bleed into the training data, thus improving the performance of the underlying models.
Rerunning the models yields the following for the 2000-2011 period:

The broad summary is that performances decline across-the-board and that the specialist models, though still generally strong performers, no longer excel in their specialism: only the 1-point model is best of all at predicting within 1 point of the final margin.
Also, it's the model using the Absolute Error metric that returns the best MAPE on the holdout sample, and that "best" is 29.80 points per game not 29.53 - still an impressive result, but now very slightly worse than the TAB Sportsbet bookmaker.
Results for the 2011 season alone are also worse than what we had previously:

Even the best margin predictor now fails to produce a sub-30 MAPE. Again though, it's the model built using the Absolute Error metric that shines, and again its performance is only a smidgeon short of the TAB Sportsbet bookmaker : 30.03 points per game versus 29.97.
Finally, note that the best-fitting models now tend to be simpler and are almost exclusively based only on the TAB Sportsbet bookmaker prices. One exception is the model that uses the square root of the absolute error, more of which in the blog that follows ...