In-Running Wagering: What's the Best Strategy?
/With services such as Betfair now offering in-running wagering opportunities, the ability to accurately assess a team's chances of victory at any given point in a game is now of considerable commercial value.
Imagine, for example, that your team, who are at home, lead by 18 points at the first change. Would a wager on them at $1.40 be advised?
In an earlier blog I built a model with which you could estimate the probability of a home team victory at any point in a game using the home team's lead or deficit at that point and the proportion of the game that had elapsed. I then proceeded to assess the quality of the model in a fairly qualitative way by comparing its probabilistic predictions with the outcomes of actual games.
There are a couple of other more quantitative approaches that we could take to assessing the quality of that model. If we simply want a crude measure of the model's predictive accuracy we could calculate how often the model correctly predicts the winning team, and if we want a measure of the quality of the model's probability assessments we could calculate its probability score, much as we do for the HELP model.
The probability score I'll use for this assessment is the logarithmic one, which you might recall assigns a score of -log(1-p), where the log is base 2, to a probabilistic prediction of p for an event which occurs. So, for example, if I assigned a probability of 0.7 to the winning team then I'd score -log(1-0.7) = 1.74 for my prediction but if, instead, I assigned a probability of 0.2 I'd score -log(1-0.2) = 0.32. The score for any single prediction will range from 0 to Infinity and a naive tip, which is one where I assign a probability of 0.5 to the event, will score 1 no matter what the outcome.
For comparative purposes I'm going to pit the model against two other simple approaches. The first, which I'll call method (A) predicts that the favourite will win and assigns this outcome a probability equal to the price of the underdog divided by the sum of the price of the underdog and the price of the favourite. The second, which I'll unsurprisingly call method (B) will predict that the team that leads will go on to win and will assign this outcome a probability equal to the proportion of total points that the leading team has scored.
As well, I'll create two hybrid predictions, one of which is an optimally weighted mixture of the probability estimates produced by methods (A) and method (B), and another which is an optimally weighted mixture of the probability estimates produced by methods (A) and the model. By weighted mixture I mean that, for example, if method (A) assigns a probability of 0.6 to an event and method (B) assigns a probability of 0.5 to that same event, if we decide to use a 50:50 mixture of the two methods out probability assessment would be 0.55.
So, that's five prediction methods in all.
Here are the results for those five methods based on the predictive accuracy metric:
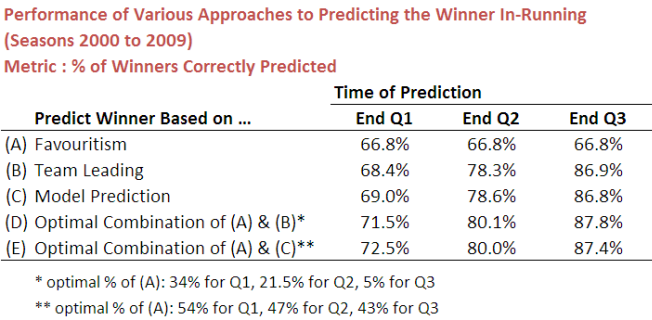
If, at the end of the first quarter, you blindly stick to the favourite, regardless of whether or not that team is leading or trailing, you'd correctly tip the winning team almost 67% of the time. It seems smarter, however, to take into account what's happened in that first quarter. One way to do that is to select whichever team leads at the first change and this would lift your predictive accuracy by a little over 1.5%.
You could also, instead, use the model we created earlier, which takes into account not just which team is in front, but by how much. This strategy would yield an accuracy of 69%.
With the hybrid or mixture strategies you could do even better, reaching 71.5% with an optimal combination of the first and second methods and 72.5% with an optimal combination of the first and third methods.
The results for the various strategies in relation to the scores at the ends of the second and third quarters are broadly similar excepting that the differences between methods (B) and (C) and between the two hybrid methods are quite small.
All of which goes to show that you could produce predictions with high accuracy using nothing more than the pre-game prices for both teams and the score at the end of any quarter.
Accuracy, however, is a very crude measure of performance. If a method produces a probability estimate greater than 50% for the eventual winner then it scores 1 for that game, and this is true if its probability estimate is 50.1% or 99.9%. Conversely, if the method produces a probability estimate less than 50% for the eventual winner then it scores 0 for that game, and this is true if its probability estimate is 49.9% or 0.1%. Such a metric doesn't give us much of an idea about how profitable a method might be if it were applied to in-running wagering.
For this purpose we need to turn to the second metric, the logarithmic probability score. Here are the results using that metric:

On this metric, a higher score connotes a better performance (and a score of 1 signifies a performance no better than guessing).
For making probabilistic predictions at the end of the first quarter, the best method combines the bookmaker's initial team prices with the predictions of our model (in about a 40:60 mix as it turns out). At the end of the second and third quarters, however, the difference between the performance of this mixture method and the method that simply uses the probability determinations of the model on their own is so small that it makes little difference which you choose.
In summary then, for in-running wagering, the best strategy would be to use the model predictions for the second half of the game and to use about a 40:60 mixture of the initial team prices and the model predictions for the first half of the game. Whether this would be a profitable strategy is an open question and one I'll look to address by following the progress of some of the in-running markets over the next few rounds.
My current hypothesis, based on casually observing a number of the in-running markets is that they adjust too slowly to underperforming favourites and too quickly to favourites that lead early. If that's right there should be value on offer for underdog teams. We'll see ...
